

기본 프로그래밍
tbESQL/C 프로그램의 문법과 실행 과정, 런타임 에러(runtime error) 처리, 그리고 tbESQL/C문장의 실행, 커서를 설명합니다.
개요
본 절에서는 tbESQL/C 프로그램의 문법과 런타임 에러 처리에 대해서 설명합니다.
tbESQL/C 프로그램의 문법
tbESQL/C 프로그램의 문법은 다음과 같습니다.
SQL 문장의 시작과 끝
tbESQL/C 프로그램에 포함되는 SQL 문장은 항상 EXEC SQL로 시작되며 세미콜론(;)으로 끝납니다.
하나의 SQL 문장은 여러 줄에 걸쳐있을 수 있습니다.
DECLARE 영역
DECLARE 영역은 'BEGIN DECLARE SECTION; '으로 시작되며, 'END DECLARE SECTION; '으로 끝납니다.
DECLARE 영역에는 변수 선언 이외에 다른 코드가 삽입되어서는 안됩니다.
SQL 문장과 함께 사용되는 입/출력 변수는 항상 DECLARE 영역에 선언해야 합니다. 입/출력 변수가 구조체나 배열의 형태로 선언된 경우에도 DECLARE 영역에 선언해야 합니다. 단, 프리 컴파일러 옵션에 따라 그렇지 않은 경우도 있습니다. 프리컴파일러 옵션에 대해서는 “tbESQL/C 프리컴파일러 옵션”을 참고합니다.
입/출력 변수가 아닌 일반적인 프로그램 변수의 경우에는 DECLARE 영역 밖에 선언되어도 무방합니다.
다음은 DECLARE 영역의 예입니다.
[예 3.1] DECLARE 영역
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR ename[24];
int salary;
VARCHAR addr[32];
EXEC SQL END DECLARE SECTION;문자열
C 프로그래밍 코드에 포함된 문자열은 큰따옴표(" ")를 사용합니다.
tbESQL/C 문장에 포함되는 문자열은 작은따옴표(' ')를 사용합니다.
연산자
SQL 문장 내에서는 SQL 문장의 표준으로 정의된 연산자만 사용할 수 있으며, C 프로그래밍 언어의 연산자는 사용할 수 없습니다. 예를 들어 비트 연산자(~, &, |, ^ 등)는 SQL 문장 내에서 사용될 수 없습니다.
다음은 SQL 논리 연산자와 C 프로그래밍 언어의 논리 연산자를 비교한 것입니다.
NOT
!
TRUE이면 FALSE, FALSE이면 TRUE를 반환
AND
&&
둘 다 TRUE일 때만 TRUE를 반환
OR
||
둘 중 하나만 TRUE이면 TRUE를 반환
=
==
두 항이 같을 경우 TRUE를 반환
주석(Comment)
주석은 C 프로그래밍 언어에서 사용하는 방법 이외에 두 개의 마이너스 부호(--)를 이용하는 방법이 있습니다.
두 개의 마이너스 부호(--)를 사용하는 주석은 부호(--)가 시작되는 곳에서부터 그 라인의 끝까지 주석으로 처리합니다. 또한 EXEC SQL 문장에만 사용될 수 있으며, C 프로그래밍 코드 부분에는 사용되지 못합니다.
다음은 주석을 사용하는 예입니다.
[예 2] tbESQL/C 프로그램에서의 주석
참조(Include)
ESQL에서 헤더 파일을 참조하는 방법으로 #include 명령과 EXEC SQL INCLUDE 명령 2가지 방법 이 있습니다.
두 명령은 각각 다른 컴파일 단계에서 쓰인다는 점에서 차이를 가지고 있습니다. 프리컴파일할 때에 필요한 인자들을 참조하기 위해선 EXEC SQL INCLUDE를 통해서 참조해야 하며, 프리컴파일 이후 만들어진 .c 파일을 컴파일할 때 필요한 헤더 파일은 #include를 통해 참조해야 합니다. 예를 들어 VARCHAR가 선언되어 있는 헤더 파일은 #include를 통해서 참조할 수 없습니다. SQLCA의 경우에는 프리컴파일할 때 자동으로 참조하게 되어 있어서 .c 파일에 남게 됩니다.
다음은 #include와 EXEC SQL INCLUDE를 사용하는 예입니다.
[예 3] tbESQL/C 프로그램에서의 참조
주의사항
ESQL 문장 내에서 사용되는 단어 혹은 그 일부를 매크로로 선언하면 프리컴파일 중 Preprocessing 과정에서 단어가 치환되어 ESQL 문장이 해석되지 않을 수 있습니다. 이를 고려하여 작성해야 합니다.
프로그램의 실행 과정
tbESQL/C 프로그램을 작성할 때는 필요한 데이터 타입이나 함수 프로토타입 등을 이용하기 위해서 반드시 sqlca.h 파일을 포함해야 합니다. 즉, 아래의 내용이 항상 tbESQL/C 프로그램 소스 코드의 맨 위에 명시 되어 있어야 합니다. 만약 존재하지 않으면 자동으로 추가됩니다.
다음 그림은 tbESQL/C 프로그램 소스 코드를 실행 파일로 생성하기 위해 거치는 전 과정입니다. 프리컴파일 과정을 제외하면 C 프로그램의 경우와 별로 다르지 않습니다.
[그림 1] tbESQL/C 프로그램의 실행 과정
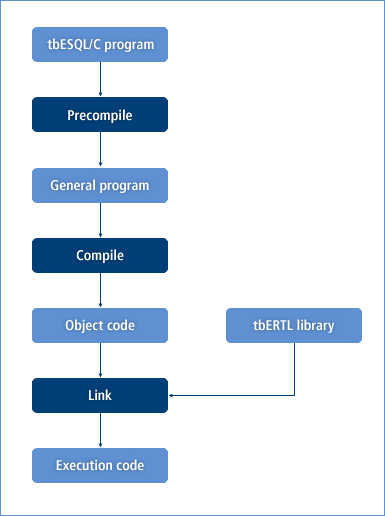
위의 [그림 1]의 과정을 순서대로 설명하면 다음과 같습니다.
tbESQL/C program tbESQL/C 프로그램을 작성한 후 작성된 소스 코드를 저장하면 .tbc 확장자를 갖는 파일이 생성됩니다.\
Precompile 작성된 프로그램을 실행하려면 먼저 프리컴파일 과정을 거쳐야 합니다. tbESQL/C의 프리컴파일러를 실행하는 명령어는 tbpc입니다.
다음은 emp.tbc 프로그램 파일에 대해 프리컴파일을 실행하는 예입니다.
[예 4] emp.tbc 프로그램의 프리컴파일
프리컴파일러를 실행하는 명령어는 옵션을 포함할 수 있습니다.
다음은 프리컴파일러 옵션을 사용하여 Include 파일의 경로를 지정하는 예입니다.
[예 5] 프리컴파일러 옵션을 사용한 Include 파일의 경로 지정
프리컴파일러 옵션에 대한 자세한 내용은 “tbESQL/C 프리컴파일러 옵션”을 참고합니다.
General program 프리컴파일의 결과로 C 프로그램 소스 코드가 생성됩니다. 이때 파일의 이름은 원본 파일의 이름과 동일하고 확장자만 '.c'로 변경됩니다. 예를 들어 emp.tbc 파일을 프리컴파일하면 emp.c라는 이름을 가진 파일이 생성됩니다.
Compile, Link 프리컴파일이 완료된 파일은 그 다음으로 컴파일 과정과 링크 과정을 거쳐야 합니다. [그림 3.1]에서는 컴파일과 링크 과정이 따로 표현되었지만, 실제로는 대개의 경우에 두 과정이 함께 수행됩니다.
다음은 [예 4]의 실행결과로 생성된 emp.c 파일을 컴파일하고 링크하는 예입니다.
[예 6] 컴파일과 링크 과정
tbESQL/C에서는 tbCLI 함수도 함께 사용하기 때문에 tbERTL 라이브러리 이외에 tbCLI 라이브러리를 함께 링크합니다. [그림 3.1]에서 링크(Link) 과정에서 링커(Linker)의 입력으로 받아들이는 tbERTL 라이브러리는 tbESQL/C의 함수 라이브러리입니다. 이 라이브러리에는 esql_do 함수 등이 정의되어 있으며, tbESQL/C 프로그램을 안전하고 효율적으로 실행하기 위한 여러 가지 작업을 수행합니다.
Execution code 컴파일 과정과 링크 과정을 거치고 나면 실행 파일이 생성됩니다.
런타임 에러 처리
tbESQL/C 프로그램 내의 SQL 문장을 실행했을 때 에러 또는 경고 등의 여러가지 예외 상황이 발생할 수 있습니다. 예를 들면 SELECT 문장의 실행 결과로 반환되는 로우가 존재하지 않거나 특정 컬럼의 일부 내용이 잘린 경우를 들 수 있습니다.
tbESQL/C 프로그램 내에서는 에러 또는 경고 상황이 발생한 경우 그에 대한 적절한 처리를 프로그램 내에서 수행할 수 있습니다.
tbESQL/C에서는 이러한 런타임 에러 처리를 위해 다음의 3가지 인터페이스를 지원합니다.
상태 변수
상태 변수(Status Variable)는 임의의 SQL 문장이 실행된 결과가 저장되는 변수
프로그램 내에서는SQL 문장을 실행한 후에 상태 변수의 값을 검토하여, 에러 또는 경고 상황의 발생을 알 수 있고, 그에 따른 처리를 수행할 수 있음
SQLCA
SQLCA(SQL 통신 영역 : SQL Communication Area)는 임의의 SQL 문장이 실행된 결과가 저장되는 구조체 변수
이 구조체는 sqlca라는 이름으로 sqlca.h 헤더 파 일에 정의되어 있으며, 상태 변수를 포함하고 있음
상태 변수와 마찬가지로 SQL 문장을 실행한 후에 SQLCA 내의 적절한 멤버 변수의 값을 검토하여 에러 또는 경고 상황의 발생을 알 수 있고, 그에 따른 처리를 수행할 수 있음
WHENEVER
WHENEVER 문장은 에러 또는 경고 상황이 발생하면 미리 정해진 특정 동작을 수행
상태 변수나 SQLCA 구조체를 이용하면 SQL 문장을 실행할 때마다 에러 또는 경고 상황이 발생하였는지 검토해야 함
하지만 WHENEVER 문장을 사용하면 tbESQL/C가 자동으로 예외 상황을 검토하고 그에 따른 처리를 수행
참고: 런타임 에러 처리에 대한 자세한 내용은 “런타임 에러 처리”를 참고합니다.
프로그램 구조
tbESQL/C 프로그램의 구조는 다음과 같습니다.
변수 선언
초기화
데이터베이스 작업
종료화
에러 처리
변수 선언
변수 선언 부분에는 “구성요소”에서 설명한 DECLARE 영역이 포함됩니다. tbESQL/C 문장에서 데이터베이스 작업에 사용될 모든 변수를 DECLARE 영역에 선언해야 합니다. 데이터베이스 작업과 관련이 없는 변수는 DECLARE 영역에 포함하지 않아도 됩니다.
다음은 변수 선언의 예입니다.
초기화
초기화 부분에서는 다음의 두 가지를 수행합니다.
런타임 에러가 발생했을 때 어떤 작업을 수행할 것인지 선언합니다. 런타임 에러가 발생했을 때 수행하는 작업에는 에러 처리 함수를 호출하는 경우, 에러를 무시하고 프로그램을 계속 진행하는 경우, 프로그램을 종료하는 경우, 특정 위치로 이동한 후 실행을 계속하는 경우등이 있습니다. 대부분의 경우에 에러 처리를 위한 함수를 미리 정의하고 그 정의된 함수를 호출합니다.
다음은 런타임 에러가 발생했을 때 tbesql_error 함수를 호출하는 예입니다.
[예 7] tbesql_error함수 호출
Tibero의 데이터베이스에 접속합니다. 데이터베이스에 접속할 때는 반드시 사용자 이름과 패스워드를 함께 명시해야 한합니다. 다음은 두 개의 입력 변수(username, password)를 이용해 데이터베이스에 접속하는 예입니다.
[예 8] 입력 변수를 이용해 데이터베이스에 접속
데이터베이스 작업
데이터베이스 작업 부분에서는 tbESQL/C 문장을 사용해 데이터베이스 질의 및 갱신을 수행합니다. 이 부분은 tbESQL/C 프로그램에서 가장 중요한 부분 중 하나입니다.
데이터베이스와 관련된 작업에는 입력 변수와 출력 변수를 많이 사용하게 됩니다. 데이터베이스 질의와 관련된 소스 코드에는 커서를 선언하고, 이 선언된 커서를 이용해 로우를 액세스하는 코드가 포함됩니다.
다음은 데이터베이스 작업 부분의 예입니다.
종료화
종료화 부분에서는 모든 데이터베이스 작업을 마치고 커밋을 수행하거나 롤백을 수행합니다.
주의
종료화 부분이 tbESQL/C 프로그램에 포함되지 않으면, 자동으로 커밋되지 않으므로 주의합니다.
다음은 데이터베이스에 부분 롤백을 수행한 뒤 커밋을 하는 예입니다.
에러 처리
에러 처리 부분에서는 런타임 에러를 처리하기 위한 코드가 포함됩니다. 에러 처리와 관련된 코드는 다른 코드와 섞여 동일한 하나의 함수 안에 포함될 수도 있으며, 별도의 함수로 정의할 수도 있습니다.
다음은 에러 처리의 예입니다.
tbESQL/C 문장 실행
본 절에서는 tbESQL/C 프로그램에서 SELECT, INSERT, UPDATE, DELETE 문장을 실행하는 방법에 대해 설명합니다.
각 문장에는 입/출력 변수가 사용되는데, 입/출력 변수는 각 문장 내에 포함된 스키마 객체와 구별하기 위하여 반드시 앞에 콜론(:)이 와야 합니다. 입/출력 변수는 이미 각 용도에 맞게 선언된 C 프로그래밍 언어의 변수이며, 이 변수를 호스트 변수라고 합니다.
SELECT
SELECT 문장은 데이터베이스에 질의를 수행하고 결과 로우를 반환하는 문장입니다. 결과 로우의 개수는 보통 하나 이상이지만 하나도 없을 수도 있습니다.
INTO 절과 출력 변수
tbESQL/C 프로그램 내에서 사용되는 SELECT 문장은 일반 SELECT 문장과 같은 문법을 가집니다. 다만SELECT 리스트 다음에 결과 로우의 각 컬럼 값을 출력 변수에 저장하기 위해 INTO 절이 삽입됩니다. 다음은 SELECT 문장의 INTO 절에 출력 변수가 사용된 예입니다.
다음은 SELECT 문장의 INTO 절에 포함되는 출력 변수에 대한 설명입니다.
컬럼 값과 출력 변수의 대응 INTO 절에 포함되는 출력 변수는 SELECT 리스트 내의 컬럼과 같은 개수이어야 하며, 지시자 변수와 함께 사용될 수 있습니다. 질의 결과로 반환된 로우의 각 컬럼 값은 컬럼 값과 동일한 순서로 대응되는 각각의 출력 변수에 저장됩니다. 출력 변수에 저장될 때 tbESQL/C 프로그램에서는 필요한 경우 데이터 타입의 변환을 수행합니다.
구조체 변수 INTO 절에 포함되는 출력 변수에는 구조체 변수를 사용할 수도 있습니다. 이때 구조체 변수에 포함된 멤버 변수의 개수는 SELECT 리스트 내의 컬럼과 개수가 같아야 합니다. tbESQL/C 프로그램에서는 결과 로우의 각 컬럼 값을 구조체 변수 내의 각 멤버 변수에 할당합니다.
로우의 개수에 따른 출력 변수 SELECT 문장의 결과 로우의 개수가 반드시 하나라는 보장이 있다면 INTO 절에 단순 출력 변수를 이용하여 처리가 가능합니다. 하지만 하나 이상인 경우에는 커서를 사용하거나 INTO 절에 출력 배열 변수를 사용해야 합니다.
참고
커서에 대한 자세한 내용은 “커서”와 “스크롤 가능 커서”, 배열 변수에 대한 자세한 내용은 “배열 변수”를 참고합니다.
다음은 결과 로우가 하나인 경우 이를 처리하는 예입니다.
위의 예에서 컬럼 EMPNO가 테이블 EMP의 기본 키 컬럼이므로 질의 결과 로우의 개수가 하나라는 것을 알 수 있습니다.
WHERE 절과 입력 변수
SELECT 문장 내에서 변수의 위치는 INTO 절에 출력 변수가 포함되는 것 외에 WHERE 절에 입력 변수가 포함됩니다.
다음은 SELECT 문장의 WHERE 절에 입력 변수가 사용된 예입니다.
다음은 SELECT 문장의 WHERE 절에 포함되는 입력 변수에 대한 설명입니다.
입력 변수의 값 설정 WHERE 절에 포함되는 입력 변수의 값은 SELECT 문장이 실행되기 전에 설정되어 있어야 합니다. 그 이유는 SELECT 문장은 실행 직전에 입력 변수의 값을 가져와서 SELECT 문장을 완성한 뒤에 실행되기 때문입니다. SELECT 문장의 실행에 필요한 입력 변수의 값은 그 문장이 실행되기 직전에 읽혀지므로, 입력 변수의 값은 프로그램 실행 중에 동적으로 설정할 수 있습니다.
입력 변수 사용의 제약 SELECT 문장의 입력 변수는 상수를 대신하여 사용할 수 있지만 스키마 객체 또는 컬럼 등의 이름을 대신하여 사용될 수는 없습니다. SELECT 문장에 부질의(Subquery)가 사용되는 경우에는 부질의 내에 출력 변수를 포함시킬 수는 없지만 입력 변수를 포함시킬 수는 있습니다.
다음은 컬럼의 이름을 대신하여 입력 변수가 사용된 예입니다.
위의 예의 맨 마지막 라인에서 WHERE 절 다음에 컬럼의 이름이 나와야 하는데, 대신 변수가 사용되었기 때문에 잘못되었습니다.
INSERT
INSERT, DELETE, UPDATE 문장은 공통적으로 질의의 결과 로우가 존재하지 않으므로 출력 변수 없이 입력 변수만을 사용합니다. INSERT 문장에서 입력 변수는 컬럼에 삽입할 데이터 값의 위치나 부질의 내부에 사용될 수 있습니다.
INSERT 문장에서 삽입하고자 하는 컬럼 값의 일부에 대해서만 입력 변수를 사용할 수도 있습니다. 다음은 일부 컬럼에 대해서만 입력 변수를 사용하는 예입니다.
삽입하고자 하는 모든 컬럼 값에 대하여 입력 변수를 사용하는 경우 구조체 변수를 사용할 수 있습니다. 이때 구조체 변수에 포함된 각 변수 값은 삽입하고자 하는 각 컬럼 값에 대응됩니다.
다음은 구조체 변수를 사용해 데이터를 삽입하는 예입니다.
또한 부질의에 입력 변수를 사용할 수도 있습니다. 다음은 부질의를 포함하는 INSERT 문장의 예입니다.
UPDATE
UPDATE 문장도 INSERT 문장과 마찬가지로 입력 변수만을 사용합니다.
UPDATE 문장에서는 SET 절의 컬럼 값의 위치나 WHERE 절에서 입력 변수가 사용될 수 있습니다. UPDATE 문장에 포함된 부질의에서도 입력 변수를 사용할 수 있습니다. UPDATE 문장에서는 INSERT 문장에서와 달리 구조체 입력 변수를 사용할 수 없습니다.
다음은 일부 컬럼 값과 WHERE 절 내에 입력 변수를 사용하는 예입니다.
다음은 부질의에 입력 변수를 사용하는 예입니다.
DELETE
DELETE 문장도 INSERT, UPDATE 문장과 마찬가지로 입력 변수만을 사용합니다. DELETE 문장에서는 WHERE 절에서 입력 변수가 사용됩니다. DELETE 문장에서도 UPDATE 문장과 마찬가지로 구조체 입력 변수를 사용할 수 없습니다.
다음은 입력 변수를 사용하는 DELETE 문장의 예입니다.
커서
본 절에서는 커서의 기본적인 사용 방법에 대하여 설명하고, 갱신 및 삭제를 위한 CURRENT OF 절을 설명합니다. 그리고 마지막으로 사용 예제를 제시합니다.
사용 방법
SELECT 문을 통한 질의를 수행할 때 WHERE 절에 기본 키 제약조건을 부여하지 않으면, 대개의 경우 결과 로우의 개수는 하나 이상입니다. 커서는 이렇게 반환된 다수의 결과 로우에 각각 차례로 액세스하기 위한 데이터 구조입니다.
다음은 커서를 사용하는 순서입니다.
커서를 사용하기 위해서는 DECLARE CURSOR를 사용해 맨 먼저 SQL 문장과 연관하여 커서를 선언해야 합니다. 커서를 선언할 때에는 항상 커서의 이름을 주어야 하며, 커서의 선언부는 그 커서를 사용하는 다른 모든 문장의 앞에 와야 합니다.
다음은 emp_cursor라는 이름으로 커서를 선언하는 예입니다.
[예 9] 커서의 선언
커서를 사용하기 위해서는 OPEN을 사용해 해당 커서를 열어야 합니다. OPEN을 실행하면 연관된 SELECT 문장이 실행되어 질의의 결과 로우가 반환됩니다. 또한 커서는 결과 로우 중에서 맨 처음에 위치한 로우의 직전을 가리킨다. 첫 FETCH가 실행되면 첫 번째 로우를 가리키게 됩니다. OPEN을 실행해서 커서를 선언할 때에 SELECT 문장에 포함된 입력 변수의 값은 OPEN이 실 행될 때 할당된다는 것에 유의합니다.
다음은 [예 9]에서 선언한 emp_cursor라는 이름의 커서에 OPEN을 실행하는 예입니다.
[예 10] OPEN의 실행
FETCH를 실행해 로우에 액세스를 합니다. OPEN의 실행으로는 아직 로우에 액세스를 할 수 있는 것은 아닙니다. 로우에 액세스를 하기 위해서는 FETCH를 실행해야 합니다. FETCH의 INTO 절에는 구조체 변수나 지시자 변수를 함께 사용할 수 있습니다.
다음은 FETCH를 실행하는 예입니다.
[예 11] FETCH의 실행
FETCH를 실행하면 먼저 커서가 다음 결과 로우를 가리키게 되고, 커서가 가리키는 결과 로우를 출력 변수에 저장합니다. FETCH를 실행할 때마다 커서는 다음 결과 로우를 가리키고, 결국 맨 마지막 결과 로우의 범위를 넘어 FETCH를 실행하면, NOT FOUND 에러가 발생합니다.
대개의 경우 FETCH를 무한 루프 안에 포함시키며, NOT FOUND 에러가 발행하면 루프를 빠져 나오도록 코드를 작성합니다. 이때 NOT FOUND 에러가 발생했을 때 루프를 빠져 나오도록 하기 위해서는 WHENEVER 문장을 사용합니다.
다음은 WHENEVER 문장을 사용하는 예입니다.
[예 12] WHENEVER 문장의 사용
WHENEVER 문장에 DO break 명령 이외에 GOTO 명령을 사용할 수도 있습니다.
OPEN을 사용해 커서를 열기 전이나 CLOSE를 사용해 커서를 닫은 후 그리고 NOT FOUND 에러가 발생한 이후에 FETCH를 실행하면 에러가 발생합니다.
FETCH를 이용해 다음 로우 뿐만 아니라 이전 로우를 액세스할 수도 있습니다. 이러한 작업을 위해서는 스크롤 가능 커서를 선언해야 한합니다. 스크롤 가능 커서에 대해서는 “스크롤 가능 커서”를 참고합니다.
커서 사용의 마지막 단계는 CLOSE를 사용해 커서를 닫는 것입니다. 커서를 닫은 이후에는 그 커서에 대해 어떠한 작업도 실행할 수 없습니다.
다음은 emp_cursor라는 이름의 커서에 CLOSE를 실행하는 예입니다.
[예 13] CLOSE 사용 예
CURRENT OF 절
커서를 이용해 SELECT 문장의 실행 결과 로우를 차례로 액세스하면서 커서가 현재 가리키고 있는 결과 로우를 삭제하거나 갱신하려고 할 때 DELETE 문장과 UPDATE 문장에 CURRENT OF 절을 사용합니다.
SELECT 문장에서 CURRENT OF 절을 사용하기 위해서는 FOR UPDATE 절을 포함해야 합니다. FOR UP DATE 절은 질의 결과로 반환된 로우에 잠금(LOCK)을 설정합니다. 잠금이 설정된 로우는 현재 트랜잭션이 커밋 또는 롤백되기 전까지는 다른 트랜잭션이 로우를 갱신하거나 삭제할 수 없습니다.
다음은 UPDATE 문장에서 CURRENT OF 절을 이용하여 컬럼 SALARY만을 갱신하는 예입니다.
커서가 현재 가리키고 있는 로우는 FETCH 문장을 실행하여 방금 전에 컬럼 값을 읽은 로우입니다.
커서에 대해 OPEN 문장을 실행한 후에 한번도 FETCH 문장을 실행하지 않았거나 모든 결과 로우를 읽고 나서 NOT FOUND 에러가 반환되었다면 커서가 현재 가리키고 있는 로우는 없습니다. 현재 가리키고 있는 로우가 없는 커서를 이용하여 DELETE 또는 UPDATE 문장을 실행하였다면 에러를 반환합니다. 또한 OPEN 문장을 수행하지 않았거나 CLOSE 문장을 이미 수행한 커서를 이용하여 삭제 또는 갱신을 시도할 때에도 에러를 반환합니다.
CLOSE_ON_COMMIT 옵션이 'YES'로 지정된 경우를 제외하고는 일반적으로 커서는 현재 트랜잭션이 커밋 또는 롤백한 후에도 사용할 수 있습니다. 즉, 커서를 이용하여 질의 결과 로우를 액세스할 수 있습니다. 하지만 FOR UPDATE 절을 포함한 SELECT 문장에 대한 커서는 사용할 수 없습니다. 왜냐하면 트랜잭션이 커밋되거 나 롤백되는 동시에 결과 로우에 설정되♘던 잠금을 해제해 버리기 때문입니다.
사용 예제
다음은 커서를 사용하는 예제 프로그램입니다.
[예 14] 커서의 사용
① tbESQL/C 문장 내에 포함되는 모든 입/출력 변수는 DECLARE 영역 안에서 선언합니다. 프로그램의 맨 앞쪽에서 커서를 선언하고 있지만, 변수의 선언과는 달리 커서의 선언은 어떠한 위치에 오더라도 상관없으며, 그 커서가 사용되기 전에만 선언되면 됩니다.
②, ④ 두 개의 커서를 선언합니다. 각각 단순 질의와 갱신을 위한 커서인데, 단순 질의를 위한 커서는 emp_cursor이고, 갱신을 위한 커서는 emp_update_cursor입니다.
③, ⑤ 변수 deptno가 두 개의 커서에 공통적으로 사용됩니다. 커서와 연관된 SELECT 문장은 OPEN 문장으로 커서를 열 때 실행되며, 그 직전에 입력 변수의 값을 읽어 들입니다. 따라서 같은 변수를 사용하더라도 각각의 SELECT 문장이 실행될 때 서로 다른 deptno 값이 적용될 수도 있습니다.
⑥ 프로그램의 맨 마지막에서는 현재 트랜잭션을 커밋합니다. 단순 질의를 위한 커서 emp_cursor는 트랜잭션 커밋 후에도 계속 사용할 수 있으나, 갱신을 위한 커서 emp_update_cursor는 사용할 수 없습니다.
스크롤 가능 커서
본 절에서는 스크롤 가능 커서(Scrollable Cursors)의 사용 방법과 예제를 설명합니다.\
사용 방법
커서는 질의의 결과 로우를 액세스할 때 항상 다음에 위치한 로우만 액세스할 수 있는 것에 비해, 스크롤 가능 커서는 임의의 로우에 액세스를 할 수 있습니다. 예를 들어 스크롤 가능 커서는 현재 커서가 가리키고 있는 로우의 바로 이전 로우를 액세스하거나 전체 결과 로우 중에서 n번째 로우를 액세스할 수 있습니다.
스크롤 가능 커서는 사용 방법의 편리성과 유연성을 제공하지만 커서와 비교했을 때 메모리 등의 리소스를 많이 사용할 수 있으므로 프로그램의 실행 성능을 떨어뜨릴 수 있습니다. 따라서 꼭 필요한 경우가 아니라면 커서를 사용하는 것이 효율적입니다.
다음은 커서와 스크롤 가능 커서의 차이점입니다.
다음 위치에 있는 로우만 차례대로 액세스
임의의 위치에 있는 로우를 액세스할 수 있음
'DECLARE {커서 이름} CURSOR'의 형태로 선언
'DECLARE {커서 이름} SCROLL CURSOR'의 형
태로 선언
FETCH를 실행할 때 옵션을 지정할 수 없음
FETCH를 실행할 때 반드시 옵션을 지정해야함
스크롤 가능 커서에서도 커서와 동일하게 OPEN과 CLOSE를 사용합니다. 스크롤 가능 커서가 현재 가리키고 있는 로우에 대하여 삭제 및 갱신을 수행하고자 할 때에도 커서와 마찬가지로 DELETE 문장과 UPDATE 문장 내에서 CURRENT OF 절을 이용합니다. 문장의 작성 및 사용 방법은 커서와 동일합니다.
커서 이름을 지정하는데는 다음 사항을 고려해야합니다.
커서 이름에 "SQLCUR", "SQL_CUR"를 포함하지 않아야 합니다.
커서 이름의 길이가 128이 넘어가지 않도록 합니다.
커서 이름의 길이이 128이 넘어가면 CLI단에서 이름을 128로 자릅니다.
커서와 스크롤 가능 커서의 차이점을 좀더 상세하게 설명하면 다음과 같습니다.
스크롤 가능 커서의 선언 스크롤 가능 커서의 선언은 SCROLL 키워드가 포함된다는 것을 제외하면 커서의 선언과 동일하며 다음과 같은 형태로 선언합니다.
다음의 소스 코드는 스크롤 가능 커서를 선언하는 예입니다.
스크롤 가능 커서에서의 FETCH의 사용 스크롤 가능 커서에서 FETCH를 사용할 때는 항상 액세스할 대상 로우를 지정해야 합니다. 다음은 FETCH에서 액세스를 할 대상 로우를 지정할 때 사용되는 옵션입니다.
NEXT
현재 커서가 가리키는 로우의 다음 로우에 액세스를 함
PRIOR 옵션과 반대 (생략 가능)
PRIOR
현재 커서가 가리키는 로우의 이전 로우에 액세스를 함
NEXT 옵션과 반대
FIRST
맨 처음에 위치한 로우에 액세스
LAST 옵션과 반대
LAST
맨 마지막에 위치한 로우에 액세스
FIRST 옵션과 반대
CURRENT
현재 로우에 액세스
RELATIVE offset
현재 커서가 가리키고 있는 로우의 다음 offset 번째에 위치한 로우에 액세스를 함
offset 값이 음수라면 커서가 현재 위치에서 앞으로 이동
예를 들어 현재 커서가 8번째 로우를 가리키고 있는데, 'FETCH RELATIVE -3'을 실행한다면 커서는 5번째 로우를 가리키게 됨
ABSOLUTE offset
전체 로우 중에서 offset 번째 로우에 액세스를 함
다음은 FETCH에 옵션을 사용하는 예입니다.
위의 예에서는 각각 순서대로 첫 번째 문장은 이전 로우를 액세스하고, 두 번째 문장은 마지막 로우를 액세스하고, 세 번째 문장은 전체 로우 중에서 세 번째 로우를 액세스하고 있습니다. 만약 액세스하고자 하 는 로우가 존재하지 않으면 NOT FOUND 에러가 반환됩니다.
사용 예제
다음은 스크롤 가능 커서를 사용하는 예제 프로그램입니다.
위의 예에서는 주석을 삽입하여 FETCH를 실행할 때마다 스크롤 가능 커서의 현재 위치를 설명하였습니다. 또 한 질의 결과 로우가 8개 이상임을 가정합니다. SQL 문장 내에 포함되는 모든 입/출력 변수는 DECLARE 영역 안에서 선언하였습니다. 커서를 선언할 때와 마찬가지로 스크롤 가능 커서를 선언하는 문장도, 스크롤 가능 커서가 사용되기 전이라면 어떤 위치에 있어도 상관없습니다.
Last updated