

복합 타입
tbPSM에서 제공하는 구조체 형태의 콜렉션 타입과 레코드를 설명합니다.
개요
복합 타입(composite type)이란 tbPSM이 제공하는 스칼라 타입의 집합입니다.
일반적인 프로그래밍 언어의 구조체에 해당하며, 그 종류는 다음과 같습니다.
컬렉션(collection) 타입 : 테이블(nested table), 인덱스 테이블(indexed by table), 배열(varray)
레코드(record)
컬렉션 타입
컬렉션이란 같은 타입을 갖는 구성요소의 집합입니다. 일반적인 프로그래밍 언어에서 사용하는 배열이나 리스트와 비슷한 개념입니다.
tbPSM에서 지원하는 컬렉션 타입에는 세 가지가 있습니다. 즉, 테이블, 인덱스 테이블, 그리고 배열입니다.
테이블
테이블은 구성요소의 길이 제한이 없고, 각각의 구성요소에 접근할 때는 배열과 마찬가지로 인덱스로 접근합니다. 그러나 배열과 다르게 구성요소가 연속적으로 존재하지 않을 수 있습니다. 즉, 어떤 구성요소의 다음 인덱스에 값이 반드시 존재합니다는 보장이 없습니다.
테이블의 구성요소는 항상 같은 타입을 가지며, REF CURSOR를 제외한 모든 타입이 될 수 있습니다. tbPSM에서 테이블을 선언하는 방법은 다음과 같습니다.
TYPE name IS TABLE OF type [NOT NULL];테이블의 초기화
테이블은 초기화라는 과정을 거치게 되는데, 이 과정을 거치지 않은 변수는 항상 NULL을 가지며, 구성요소도 존재하지 않게 됩니다. 만약 초기화되지 않은 테이블에 접근할 경우 COLLECTION_IS_NULL 예외 상황이 발생합니다.
테이블을 초기화하는 방법은 다음과 같습니다.
테이블의 구성요소
테이블은 최대 크기의 제한이 없기 때문에 초기 값으로 주어진 구성요소가 현재의 최대 길이가 됩니다. 만약 테이블에서 NOT NULL 제약조건이 없을 경우 NULL을 구성요소로 사용할 수 있습니다.
테이블의 구성요소는 하나의 독립적인 변수처럼 사용할 수 있으며, 해당 변수의 값을 추출할 수 있습니다. 또한 대입도 가능합니다.
예를 들면 다음과 같습니다.
테이블의 구성요소를 참조하기 위해서는 다음과 같이 사용해야 합니다.
index에는 1 ~ 2^31 - 1사이의 값만을 사용할 수 있습니다.
MULTISET 연산자
테이블 형태의 변수에는 MULTISET 연산자의 결과를 대입할 수 있습니다. MULTISET 연산자로는 UNION, INTERSECT, EXCEPT 세 가지가 있습니다.
UNION은 MULTISET 연산자의 두 테이블을 합쳐줍니다. 합칠 때 중복값의 제거 여부를 옵션으로 결정할 수 있습니다. ALL과 DISTINCT의 두 가지 옵션이 있으며, ALL 옵션은 중복되는 값을 제거하지 않습니다. 반면 DISTINCT 옵션은 중복되는 값을 제거합니다. 옵션을 주지 않으면 ALL과 같이 동작합니다.
MULTISET UNION 에 의해 tab1과 tab2의 구성요소들이 합쳐져 result 테이블에 저장됩니다. 옵션은 ALL이 므로 중복값을 제거하지 않아, 이 테이블은 1, 2, 3, 1, 4, 5의 여섯 개 구성요소를 갖습니다.
ALL 혹은 DISTINCT 옵션을 사용하지 않은 경우 위 예제의 ALL 옵션과 동일하게 동작합니다. result 테이블은 1, 2, 3, 1, 4, 5의 여섯 개 구성요소를 갖습니다.
DISTINCT 옵션을 사용한 경우 MULTISET 연산자의 결과에서 중복된 구성요소는 제거됩니다. result 테이블은 1, 2, 3, 4, 5의 다섯 개 구성요소를 갖습니다.
INTERSECT는 MULTISET 연산자의 두 테이블 사이에 공통된 구성요소를 찾아줍니다. 중복값의 제거 여부를 옵션으로 결정할 수 있습니다. ALL과 DISTINCT의 두 가지 옵션이 있으며, ALL 옵션은 중복되는 값을 제거하지 않는다. 반면 DISTINCT 옵션은 중복되는 값을 제거합니다. 옵션을 주지 않으면 ALL과 같이 동작합니다.
MULTISET INTERSECT에 의해 tab1과 tab2의 구성요소들 중 공통된 구성요소를 찾아 result 테이블에 저장됩니다. 옵션은 ALL이므로 중복값을 제거하지 않아, 이 테이블은 1, 1, 2의 세 개 구성요소를 갖습니다.
ALL 혹은 DISTINCT 옵션을 사용하지 않은 경우 위 예제의 ALL 옵션과 동일하게 동작합니다. result 테이블 은 1, 1, 2의 여섯 개 구성요소를 갖습니다.
DISTINCT 옵션을 사용한 경우 MULTISET 연산자의 결과에서 중복된 구성요소는 제거됩니다. result 테이 블은 1, 2의 두 개 구성요소를 갖습니다.
EXCEPT는 MULTISET 연산자의 앞 테이블에는 있으면서 뒤 테이블에는 없는 구성요소를 찾아줍니다. 중복값의 제거 여부를 옵션으로 결정할 수 있습니다. ALL과 DISTINCT의 두 가지 옵션이 있으며, ALL 옵션은 중복되는 값을 제거하지 않습니다. 반면 DISTINCT 옵션은 중복되는 값을 제거합니다. 옵션을 주지 않으면 ALL 과 같이 동작합니다.
MULTISET EXCEPT에 의해 tab1의 구성요소이면서 tab2의 구성요소는 아닌 값들만 result 테이블에 저장됩니다. 옵션은 ALL이므로 중복값을 제거하지 않아, 이 테이블은 3, 3의 두 개 구성요소를 갖습니다.
ALL 혹은 DISTINCT 옵션을 사용하지 않은 경우 위 예제의 ALL 옵션과 동일하게 동작합니다. result 테이블 은 3, 3의 두 개 구성요소를 갖습니다.
DISTINCT 옵션을 사용한 경우 MULTISET 연산자의 결과에서 중복된 구성요소는 제거됩니다. result 테이 블은 3의 한 개 구성요소를 갖습니다.
인덱스 테이블
인덱스 테이블은 키와 값이 합쳐진 구성요소를 갖는 테이블입니다. 각각의 구성요소에 접근할 때에는 숫자 또는 문자열을 이용하여 인덱스로 접근합니다. 인덱스 테이블의 구성요소는 PLS_INTEGER, BINARY_IN TERGER, VARCHAR2, STRING, LONG 타입이어야 합니다.
tbPSM에서 인덱스 테이블을 선언하는 방법은 다음과 같습니다.
인덱스 테이블의 사용
인덱스 테이블은 선언할 때 최대 크기의 제한이 없습니다. 인덱스 테이블의 크기는 인덱스가 동일하게 설정된 키에 값을 삽입하는 경우 이전 값이 변경되므로 증가하지 않습니다. 반면에 인덱스가 다르게 설정된 키에 값을 삽입하는 경우 인덱스 테이블의 크기는 증가하게 됩니다.
배열
배열은 테이블과 달리 선언할 때 길이의 제한이 있습니다. 따라서 선언할 때 반드시 길이를 지정해야 합니다. 그리고 각각의 구성요소는 항상 연속적으로 존재하며, 구성요소에 접근할 때에는 인덱스로 합니다.
배열은 모든 구성요소가 서로 동일한 타입이어야 합니다. REF CURSOR를 제외한 모든 타입이 될 수 있습니다. 또한 배열을 구성요소 타입으로 갖는 배열을 선언할 수 있습니다.
tbPSM에서 배열을 선언하는 방법은 다음과 같습니다.
배열의 초기화
배열은 초기화라는 과정을 거치게 되는데, 이 과정을 거치지 않은 변수는 항상 NULL을 가지며, 구성요소도 존재하지 않게 됩니다. 만약 초기화되지 않은 배열에 접근할 경우 COLLECTION_IS_NULL 예외 상황이 발생합니다.
배열을 초기화하는 방법은 다음과 같습니다.
배열의 구성요소
배열은 선언할 때 지정한 길이가 구성요소의 최대 길이가 되므로, 초기화되지 않은 나머지 구성요소는 존재하지 않는 값이 됩니다. 만약 초기화되지 않은 구성요소에 접근할 경우에는 BEYOND_SUBSCRIPT 예외 상황이 발생합니다. 만약 배열에서 NOT NULL 제약조건이 없을 경우에는 NULL을 구성요소로 사용할 수 있습니다.
배열의 구성요소는 하나의 독립적인 변수처럼 사용할 수 있으며, 해당 변수의 값을 추출할 수 있습니다. 또한 대입도 가능합니다.
예를 들면 다음과 같습니다.
배열의 구성요소를 참조하기 위해서는 다음과 같이 사용해야 합니다.
index에는 1 ~ 2^31 - 1 사이의 값만을 사용할 수 있습니다.
참고
배열은 IS NULL 연산자와 등호 연산자만 사용할 수 있습니다. 대소 비교와 같은 일반적인 비교 연산은불가능합니다.
컬렉션 함수와 프러시저
tbPSM은 컬렉션 타입을 쉽고 편하게 사용하기 위해 컬렉션 함수와 프러시저를 제공합니다.
컬렉션 함수
EXISTS
COUNT
LIMIT
FIRST, LAST
PRIOR, NEXT
컬렉션 함수는 항상 반환값을 가짐
프러시저
EXTEND
TRIM
DELETE
프러시저는 반환값을 갖지 않음
컬렉션 함수와 프러시저를 초기화되지 않은 컬렉션 변수에 사용하는 경우 COLLECTION_IS_NULL 예외 상황이 발생합니다.
EXISTS 함수
EXISTS 함수는 n-번째 구성요소의 존재 여부를 TRUE, FALSE로 반환합니다. 이 값은 DELETE 프러시저에 의해 달라질 수 있습니다.
다음은 EXISTS 함수의 예입니다.
COUNT 함수
COUNT 함수는 컬렉션 변수의 구성요소 개수를 반환합니다. 이 값은 DELETE 프러시저에 의해 달라질 수 있습니다.
다음은 COUNT 함수의 예입니다.
LIMIT 함수
LIMIT 함수는 컬렉션 타입에 따라 반환되는 값이 다릅니다.
테이블, 인덱스 테이블
구성요소의 길이 제한이 없으므로 NULL을 반환
배열
배열을 선언할 때 지정된 값이 반환됨
다음은 LIMIT 함수의 예입니다.
FIRST, LAST 함수
FIRST 함수는 첫 번째 구성요소의 인덱스를 반환하고, LAST 함수는 마지막 구성요소의 인덱스를 반환합니다. 이 값은 DELETE 프러시저에 의해 달라질 수 있습니다.
FIRST, LAST 함수는 컬렉션 타입에 따라 반환되는 값이 다릅니다.
인덱스 테이블
FIRST 함수 : 가장 낮은 키값을 갖는 테이블을 반환
LAST 함수 : 가장 높은 키값을 갖는 테이블을 반환
배열
FIRST 함수 : 항상 1을 반환
LAST 함수 : 항상 COUNT 함수와 같은 값을 반환
다음은 FIRST, LAST 함수의 예입니다.
PRIOR, NEXT 함수
PRIOR 함수는 n-번째 구성요소의 바로 앞에 구성요소 인덱스를 반환하고, NEXT 함수는 n-번째 구성요소의 바로 다음의 구성요소 인덱스를 반환합니다. 컬렉션 타입 중 인덱스 테이블은 키값의 순서에 따라 PRIOR, NEXT 함수의 값을 반환합니다. 이때 키값의 순서는 기본적으로 키값의 바이너리 값을 비교할 때 정해집니다.
n의 값은 EXTEND, TRIM, DELETE 프러시저에 의해 달라질 수 있습니다. n의 값에 따라 각 함수는 반환하는 값이 다음과 같이 다릅니다.
PRIOR
n < 1
NULL
LAST보다 클 경우
항상 LAST 함수의 값을 반환
NEXT
n < 1
1
LAST보다 클 경우
NULL
다음은 PRIOR, NEXT 함수의 예입니다.
EXTEND 프러시저
EXTEND 프러시저는 테이블이나 배열의 크기를 늘리기 위해 사용됩니다.
사용하는 방법은 다음과 같이 세 가지가 있습니다.
EXTEND
하나의 NULL 구성요소를 추가
EXTEND(n)
n개의 NULL 구성요소를 추가
EXTEND(m, n)
n번째 구성요소를 m개 추가
다음은 EXTENT 프러시저의 예입니다.
TRIM 프러시저
TRIM 프러시저는 배열이나 테이블의 크기를 줄이기 위해 사용됩니다.
사용하는 방법은 다음과 같이 두 가지가 있습니다.
방법
설명
TRIM
뒤에서부터 하나의 구성요소를 제거
TRIM(n)
뒤에서부터 n개의 구성요소를 제거
만약 n의 크기가 큰 경우에는 SUBSCRIPT_BEYOND_COUNT 예외 상황이 발생
다음은 TRIM 프러시저의 예입니다.
DELETE 프러시저
DELETE 프러시저는 특정 인덱스의 구성요소를 제거하거나 전체 구성요소를 제거하기 위해 사용됩니다.
사용하는 방법은 다음과 같이 세 가지가 있습니다.
DELETE
전체 구성요소를 제거
DELETE(n)
테이블 : 테이블에서 n번째 구성요소를 제거
인덱스 테이블 : 키값이 n인 값을 제거
DELETE(m, n)
테이블 또는 인덱스 테이블에서 m부터 n까지의 구성요소를 제거
m이 n보다 크거나 m과 n 중 하나라도 NULL이면 어떠한 값도 제거되지 않음
다음은 DELETE 프러시저의 예입니다.
예외 상황
컬렉션 타입과 관련된 예외 상황을 정리하면 다음과 같습니다.
COLLECTION_IS_NULL
초기화되지 않은 컬렉션 변수에 접근하는 경우
NO_DATA_FOUND
DELETE 프러시저에 의해 제거된 구성요소에 접근하는 경우 또 는 인덱스 테이블에 존재하지 않는 값에 접근하는 경우
SUBSCRIPT_BEYOND_COUNT
인덱스가 구성요소의 개수를 초과한 값으로 주어진 경우
SUBSCRIPT_OUSIDE_LIMIT
인덱스가 허용 범위를 벗어난 경우
VALUE_ERROR
인덱스가 NULL이거나 숫자의 형태로 변환이 안 되는 경우
레코드
레코드는 관련 있는 구성요소의 집합인데, 일반적인 프로그래밍 언어의 구조체와 동일합니다. 레코드에 소속된 모든 구성요소의 타입이 서로 같을 필요가 없습니다. 또한 필드가 다시 레코드를 포함할 수도 있습니다.
레코드는 주로 데이터베이스 테이블의 로우 전체를 저장하기 위해 사용됩니다. “기타 타입”에서 설명한 내용 중에서 %ROWTYPE은 레코드의 대표적인 예입니다.
레코드를 선언하는 방법은 다음과 같습니다.
레코드는 일반적으로 다음과 같은 특성이 있습니다.
레코드는 컬렉션 타입과 달리 초기화 과정이 필요 없습니다.
선언과 동시에 메모리가 할당되어 각각의 필드에 직접 접근할 수 있습니다.
레코드 변수는 소속된 필드의 타입이 모두 같을 경우에만 대입할 수 있습니다.
레코드 내부에 포함된 각 필드는 일반적인 변수와 동일하게 취급됩니다.
레코드는 NULL의 허용 여부뿐만 아니라 등호, 부등호 등의 비교가 불가능합니다.
만약 이러한 비교가 필요하다면, 두 개의 레코드를 파라미터로 전달 받아 필드를 직접 비교하는 함수를 작성해야 합니다.
다음은 레코드 선언의 예입니다.
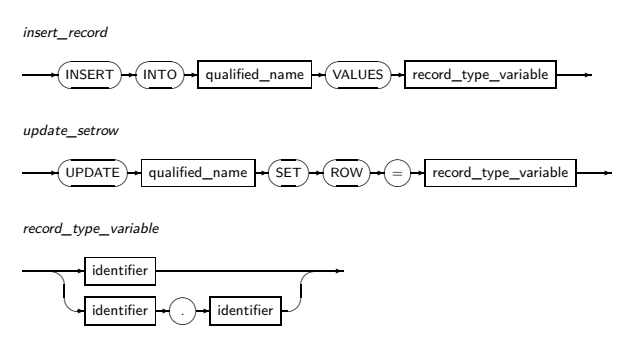
레코드 타입 변수의 DML
레코드는 테이블의 로우와 유사한 형태를 갖습니다. 이러한 특징으로 PSM에서는 DML 문에서 특별한 문법을 사용할수 있는데, 켐코드 타입의 변수를 DML에 사용하여 ROW를 삽입 또는 변경 가능합니다.
문법
예제
Last updated