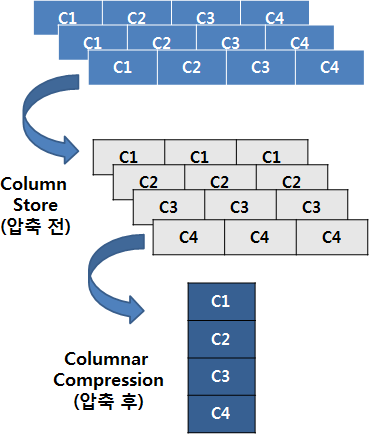
그림 1. TCC 구성(Compression Unit)
그림 1. TCC 구성(Compression Unit)
| 파라미터 | 설명 |
|---|---|
| CC_CU_BLKCNT | CU(Compression Unit)가 가질 수 있는 최대 블록 개수입니다. 보통은 큰 CU가 압축에 유리하지만, 어느 정도 이상이 되면 많이 차이가 나지 않습니다. 불필요하게 CU가 크면 반복적인 압축 해제가 있는 경우 불리하게 작용할 수도 있습니다. DB_FILE_MULTIBLOCK_READ_COUNT보다 작게 설정하는 것을 권장합니다. (기본값: 4, 범위: 1 - 32) |
| CC_CU_PCTUSE | CU에 들어갈 최소 용량 비율입니다. CU를 구성할 때 최소 이 비율 이상을 채웁니다. 이 값이 크면 공간 낭비를 막을 수 있는 반면, 로딩할 때 재압축이 많아져서 성능이 저하될 수 있습니다. (기본값: 95, 범위: 0 - 99) |
| CC_TYPICAL_ROW_SIZE | 압축될 데이터의 일반적인 row 크기입니다. 처음 압축을 시작할 때에 힌트로 사용됩니다. 이 값과 CC_EXPECTED_RATE를 이용해서 한 CU에 몇 개의 row가 들어갈지 예측해서 압축을 더 빠르게 진행시킬 수 있습니다. (기본값: 100, 범위: 3 - 1000) |
| CC_EXPECTED_RATE | 압축될 데이터의 일반적인 압축 비율입니다(힌트). CC_TYPICAL_ROW_SIZE와 함께 처음 CU를 구성할 때 쓰입니다. 이후 CU에 대한 예측은 직전 CU의 결과를 이용합니다. (기본값: 25, 범위: 1 - 100) |
| CC_CU_WRITEOUT_THRESHOLD | CC_CU_WRITEOUT_THRESHOLD는 단일 블록이 쓰기 작업을 진행하기 위해 충족해야 하는 최소 채움 비율을 지정하는 설정입니다. 즉, 블록의 데이터가 설정된 비율 이상 채워졌을 때에만 해당 블록이 디스크에 기록됩니다. (기본값: 85, 범위: 0 - 99) |