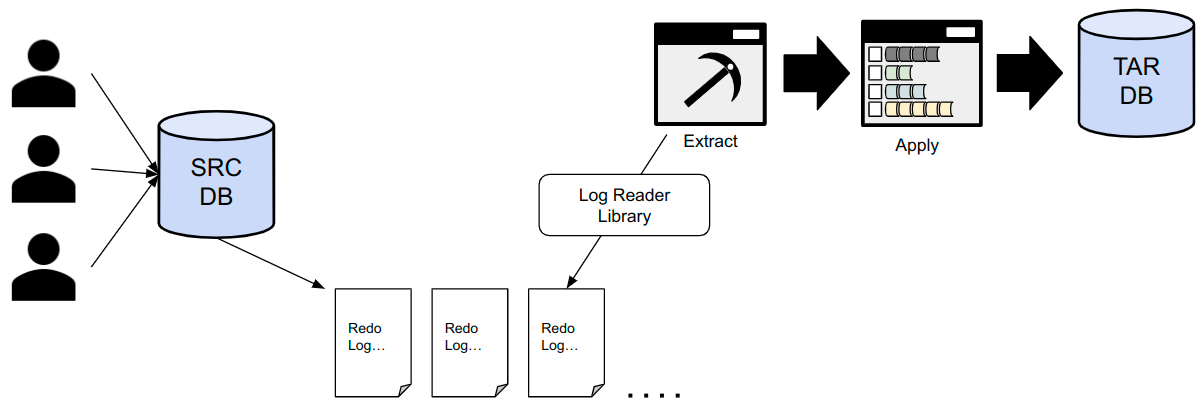
ProSync는 위와 같은 설계를 가지고있다. 전체 설계에 대한 간단한 요약을 하면 아래와 같다.
`Extract` 프로세스는 `SRC DB` 에 해당하는 추출 데이터베이스( `SRC DB` ) 에서 `Redo Log` 를 추출한다. 추출은 각 `DB` 별 `Log Reader Library` 를 통해 진행하며, 필요한 경우, 각 `DB` 별로 제공하는 별도의 로그 분석 기능을 통해 추출을 진행하기도 한다. 추출된 데이터는 `Apply` 프로세스로 전달된다.
데이터는 보통 `레코드` 단위 (쉽게 말해 `DML` 단위)로 남게되며, 해당 데이터는 `Apply` 프로세스에서 트랜잭션 별로 취합해 반영해주어야 한다. 따라서 `Apply` 프로세스는 `레코드` 들을 전달받아 트랜잭션 별로 모아둔다. `commit`에 해당하는 `레코드` 가 오게되면, 트랜잭션을 반영시킨다.
###
***
## Data Flow
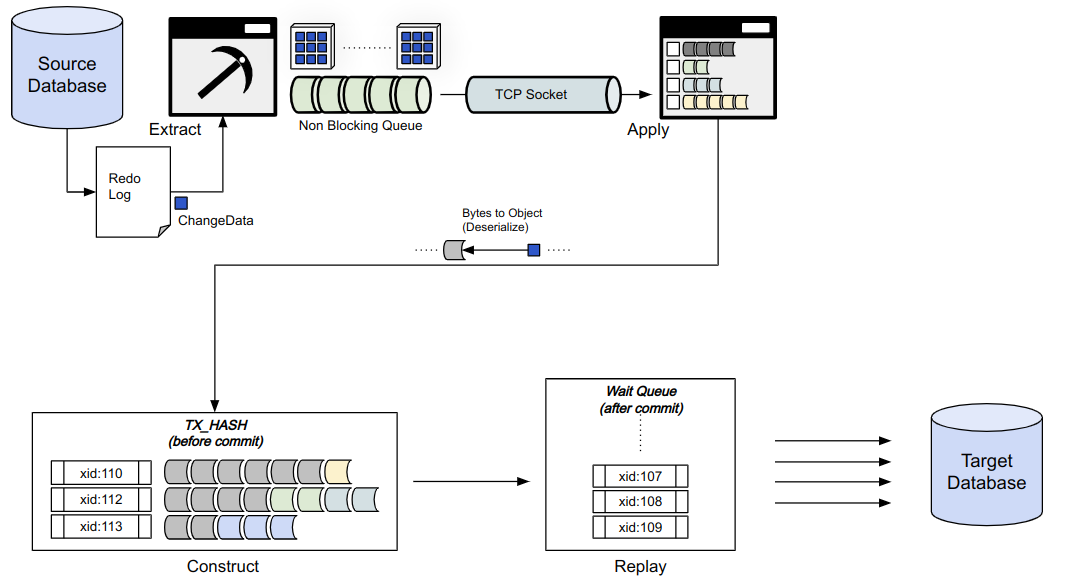
그림2. ProSync DataFlow
ProSync의 Data Flow를 기준으로 살펴보면 조금 더 상세한 과정을 볼 수 있다.
`Extract` 프로세스는 `레코드` 를 ***chunk*** 단위로 모아 `Apply` 프로세스로 전달한다. 전달받은 `Apply` 프로세스는 각 `레코드` 들을 트랜잭션 단위로 모아준다. `commit` 레코드가 올 경우 반영 데이터베이스(`TAR DB`) 로 반영하게 된다.
{% hint style="info" %}
**참고**
더욱 상세한 내용은[ 'Memory Control' ](https://docs.tibero.com/prosync/4.5_manual/administration/apply/key-features/flow-control/memory-control)를 참고한다.
{% endhint %}
###
***
## Inter Processes/Threads Communication
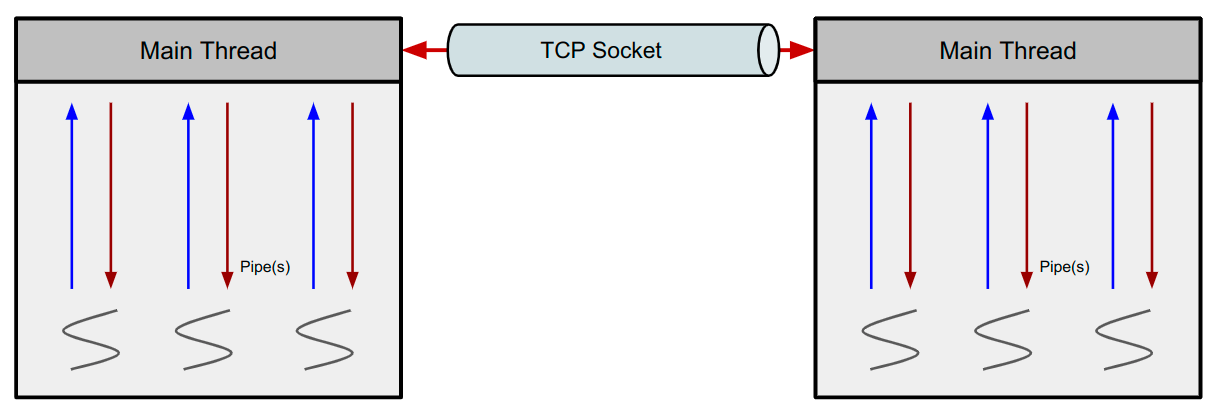
ProSync는 프로세스간 통신은 `TCP` 통신을 사용하고, 쓰레드간 통신은 `Pipe` 를 사용하여 통신한다.
그림3. Inter process & Inter thread communication in Prosync.
어떤 종류의 프로세스건, `Main` 쓰레드는 반드시 존재하고 (ProSync에선 `CTH` 혹은 `Control Thread` 라고 부른다.) 해당 쓰레드가 다른 쓰레드와의 통신을 모두 담당한다. 즉, A라는 쓰레드에서 B라는 쓰레드와 직접 통신하는건 불가능하고, 반드시 `Main` 쓰레드를 거쳐서 통신을 하게 되어있다.
또한 프로세스간 통신에선 `TCP` 로만 통신을 진행하게되며, 이에 대한 소켓의 `connect` 와 `accept` 는 모두 각 프로세스의 `Main` 쓰레드가 담당한다.
###
***
## ProSync Processes
전체 프로세스들의 기능과 구조를 간단하게 설명한다.
{% hint style="info" %}
**참고**
각 프로세스에 대한 내용은 ['운영 가이드' ](https://docs.tibero.com/prosync/4.5_manual/administration)를 참고한다.
{% endhint %}
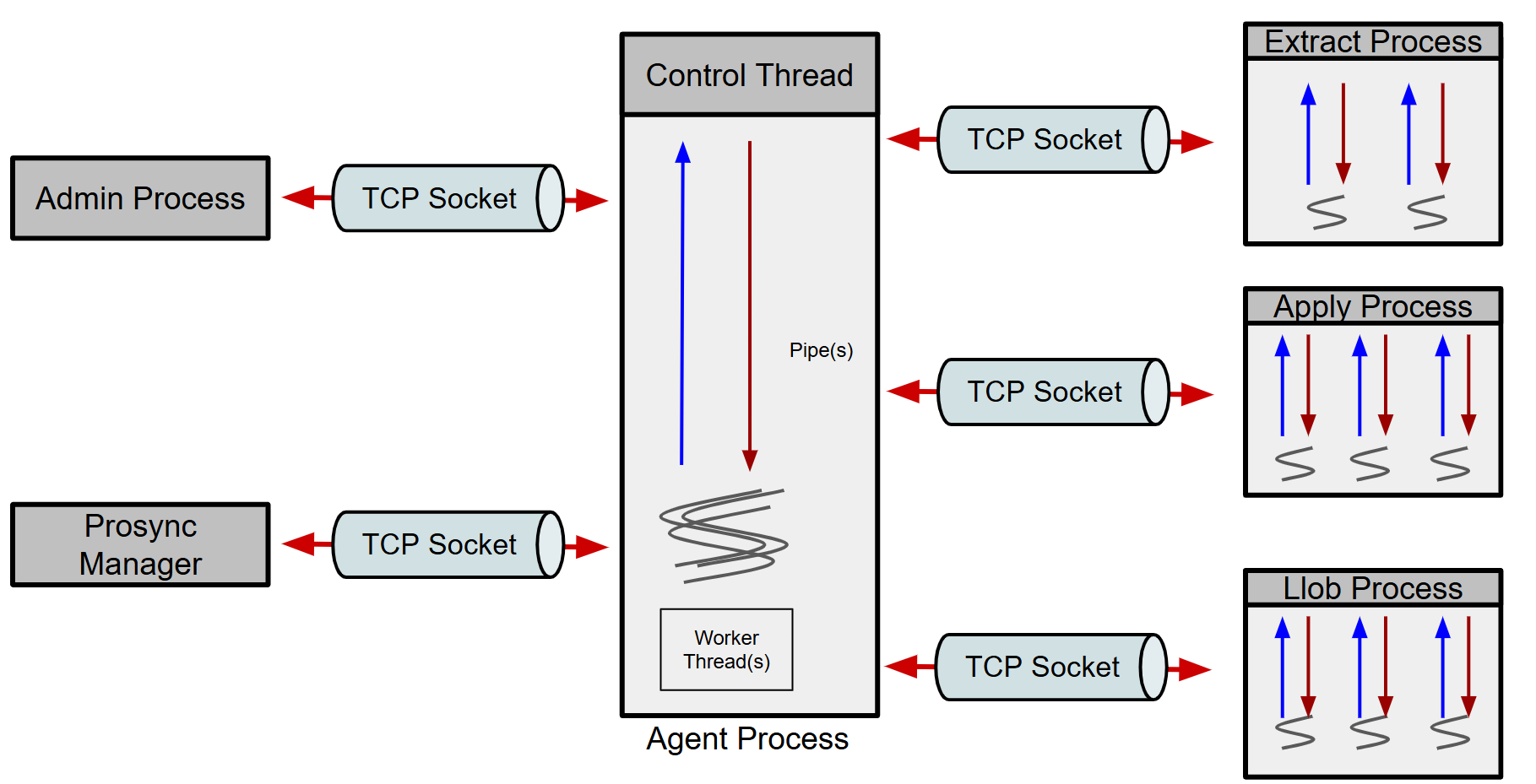
`Data Flow` 를 기준으로 설명했던 프로세스는 주로 `Extract` 프로세스와 `Apply` 프로세스이다. 물론 이 두 프로세스가 ProSync의 핵심 프로세스이긴 하지만, 프로세스 전체를 관리하고, 데이터를 수집하여 모니터링 툴에 전달해주는 등의 기능을 해주는 `Agent` 프로세스나, Long 혹은 Lob 데이터 처리를 위해 별도로 구성된 `Llob` 프로세스, `Agent` 프로세스를 통해 실제 프로세스에 명령을 내리는 `Admin` 프로세스에 대한 구성을 알아야 이후에 나올 내용들에 대한 이해가 쉽다.
전체 구성을 보면 아래와 같다.
그림4. Prosync Processes
각 프로세스에 대한 간단한 역할은 아래와 같다.
### Admin Process
`Agent` 프로세스를 통해 다른 프로세스에게 명령을 내린다. `Agent` 에게 내린 명령과 리턴을 터미널에서 출력한다고 이해할 수 있다.
명령어 목록은 [admin](https://docs.tibero.com/prosync/4.5_manual/administration/admin "mention") 메뉴얼을 참고한다.
### Agent Process
프로세스 관리에 들어가는 다양한 업무를 여기서 모두 수행한다. 대표적으로 아래와 같은 작업들이 있다.
* 프로세스 기동 / 종료
* 프로세스 별 리소스 모니터링
* 프로세스 설정 변경
이외에도 관리에 해당하는 작업은 모두 이곳에서 작업을 수행해준다.
### Extract Process
CDC 에 있어서 변경 데이터를 캡쳐하는 프로세스이다. 현재는 RDBMS의 리두로그를 보고 데이터를 추출하는 작업을 수행한다.
### Apply Process
변경된 데이터를 peer쪽에 반영하는 작업을 수행한다.
### Llob Process
RDBMS에서 사용되는 Long 혹은 Lob 과 같은 큰 단위의 데이터는 변경분의 데이터도 크다. 따라서 데이터가 리두에 남는다 하여도, 트랜잭션 말미에는 데이터가 삭제가 되거나 혹은 크게 변경될 가능성이 있다.
트랜잭션 단위로 봤을 땐, 마지막 형상의 데이터만 알아도 ACID를 유지하는 데에는 아무 문제가 없다. 모든 변경분의 데이터를 추적하지 않아도 ACID가 유지가 된다는 뜻은 처리성능(Throughput)을 불필요하게 희생하면서까지 연산을 수행할 필요는 없다는 의미이다.
`Llob` 프로세스에서 주로 수행하는 일은 `Commit` 이 들어온 시점에 `Flashback` 쿼리를 수행하여 해당 시점 즉 트랜잭션이 종료되는 시점에서의 데이터만 조회하여 `Apply` 에서 발생하는 데이터 처리량을 줄이고, 전체 동기화 과정에서의 부하를 줄여주는 프로세스이다.
###
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.tibero.com/prosync/4.5_manual/introduction/architecture.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.